Flink应用(1)
1 Flink与大数据计算
Flink以Stream模型为基础对数据计算进行建模,为批和流的处理实现了统一。并在低延迟、稳定性、编程接口友好等方面具有较大的优势,是大数据实时计算的利器。从下图(摘自官方)可以看出,Flink将来自各个数据源(Source)的数据进行计算,让后将结果交给各个下游数据宿(Sink)进行后续消费。同时,对于Source和Sink也可以是Flink计算应用,进行更复杂的级联,构建更丰富的数据处理模式。
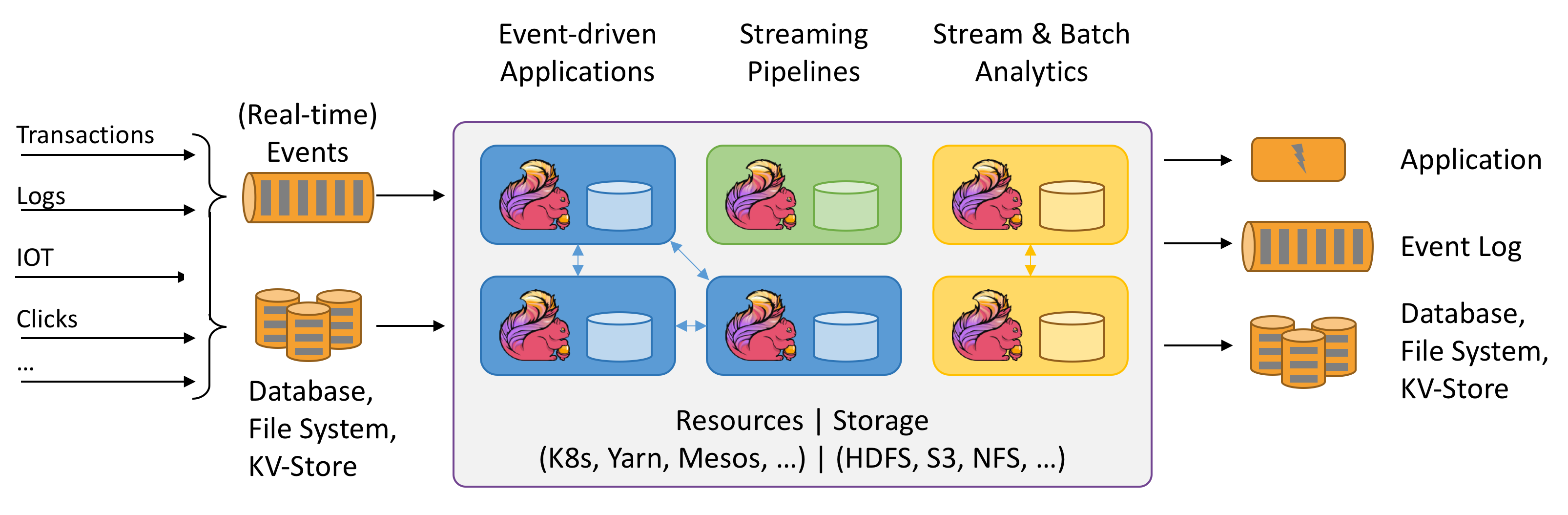
Flink有较多的线上应用背书,其优化版本Blink经历过阿里巴巴生产环境双11考验,实现了每秒4亿次计算、分钟级(1分钟以内)延迟的目标。并且,随着Blink SQL逐步集成到开源Flink项目中,其通用性和易用性都具有较大的提升,相信越来越多的大数据计算会利用Flink来构建。
下面先介绍一个简单的单机计算应用Demo。
2 单机计算应用
这部分将通过创建简单的计算应用到创建真实的PV、UV计算应用,来体验Flink。
2.1 下载并启动Flink
首先下载并启动Flink,这一步并非必须,只是为了更好的在单机进行集群模拟体验。
wget http://mirror.bit.edu.cn/apache/flink/flink-1.8.1/flink-1.8.1-bin-scala_2.12.tgz
tar zxf flink-1.8.1-bin-scala_2.12.tgz
cd flink-1.8.1/bin
./start-cluster.sh
Windows下比较简单,下载解压后通过start-cluster.bat进行启动。
通过上述start-cluster启动脚本输出情况,判断是否启动正常,并访问http://127.0.0.1:8081查看Flink工作情况。
2.2 编写简单的计算应用
计算应用可以选择Java或Scala语言来编写。根据使用不同层面的API,可以选择低级别的functor和高级别的SQL来实现计算逻辑。
下面通过Scala编写的简单PV、UV计算来进行说明。
首先,参考这里使用maven模板创建应用:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.8.0
根据archtype生成project通过
mvn idea:idea
创建idea项目文件,导入idea。
修改StreamingJob如下:
package me.xjump
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamingJob {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val words = text.flatMap {
_.toLowerCase.split("\\W+")
.filter {
_.nonEmpty
}
}
val count = words
.map {
(_, 1)
}
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
count.print
env.execute("Flink Streaming Scala demo1")
}
}
2.3 测试&调试计算应用
启动nc监听socket
#windows
nc -l -p 9999
#*nix
nc -lk 9999
然后,启动Flink计算应用,也就是启动上述StreamingJob的main,可以在idea中直接运行main函数。
注意顺序不要弄反了,否则可能导致StreamingJob启动失败。
在nc命令窗口输入
I like apple, you like orange.
go go go
Flink streaming job.
然后在StreamingJob的控制台看到计算结果:
2> (i,1)
10> (like,2)
7> (you,1)
10> (apple,1)
7> (orange,1)
8> (go,3)
2> (streaming,1)
12> (job,1)
10> (Flink,1)
在idea中下断点,可以对StreamingJob进行调试。
2.4 编写实用的计算应用
现在,让我们来实现带滑动窗口的PV、UV计算应用。
首先,需要对Flink中的几个核心的概念进行介绍。
2.4.1 时间
实时计算的一个核心数据维度是时间。时间是流的固有属性,有了时间,数据才能真正被描述成流动的,基于流的计算,本质上是基于某个时间区间的数据处理,以提取该区间内数据的某种商业特征为目标。Flink中的时间分为3种类型:
-
Event Time指的是时间发生的时间。对于Flink应用,EventTime将通过Event的生产者指定,如通过附加在Event数据中的一个字段来指定。由于这个时间是Event的生产者指定的,所以原则上是无法保证正确性的,Flink应用100%完全信任这个时间。通常在Flink应用中解析提取该字段后进行应用。 -
Processing Time指的是执行计算的Flink节点进行某个operation时的时间,从该计算节点的系统时钟来获取。 -
Ingest Time指的是Source操作获取到Event时,进行Source操作的时间,从该Source操作节点的系统时钟来获取。
2.4.2 窗口
窗口(Window)又可以理解为时间区间,Flink中的窗口有4种:
Tumbling Window可以翻译为滚动窗口。指的是按照一定的区间长度来切分时间,并且区间的起点、终点都是固定的。比如每天从00:00:00到23:59:59,或者每分钟,每小时等等。窗口对应的时间区间起点、终点是固定的,区间长度也是固定的。例如
TumblingProcessingTimeWindows.of(Time.seconds(5))
表示以ProcessingTime为基准,每5秒一个滚动窗口来创建window。
Sliding Window可以翻译为滑动窗口。指的是按照一定的区间长度来切分时间,但区间的起点、终点都是在移动的。比如最后15分钟,最后一周,最后3小时等等。窗口对应的时间区间只有长度固定,而起点、终点都不固定。例如
SlidingEventTimeWindows.of(Time.seconds(30), Time.seconds(1))
表示以EventTime为基准,30秒为滑动窗口长度,最小滑动单位为1秒来创建window。Flink可以指定的最小滑动单位的最小值是1毫秒。
Session Window可以翻译为会话窗口。指的是按照相邻两个时间的时间间隔为窗口边界,但区间的起点、终点都是不固定的。比如最小间隔为10秒,那么相邻事件超过10秒的将归为不同的窗口。例如
ProcessingTimeSessionWindows.withGap(Time.minutes(10))
表示以ProcessingTime为基准,10分钟为Gap(时间间隔)来创建window。该窗口起点和终点都不固定,长度也不固定,但如果相邻两个事件间隔超过了10分钟,那么后一个事件将属于一个新的窗口。
又例如
DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
})
表示以ProcessingTime为基准,从一个String为Event对象的事件中动态提取窗口间隔值,来动态的创建会话窗口。
Global Window可以翻译为全局窗口。指的是时间区间是无界的。全局窗口通过如下方式创建
GlobalWindows.create()
2.4.3 计算PV和UV
有了上述时间和窗口的概念,计算PV和UV可以翻译为:在一定的时间内,访问某个URL的次数和用户数。由于一个URL被访问一次可以直接计数,但多个URL被多个用户访问,可能存在用户访问多个URL的情况,所以对于用户的计数是要去重的,也就是需要进行Distinct Count。
这里窗口选择上可以是翻滚窗口,也可以是滑动窗口,看需要而定。
修改StreamingJob如下
package me.xjump
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.extensions._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger
object StreamingJob {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val dataInput = text.map(x=> {
val it = x.split(",")
.filter {
_.nonEmpty
}
it // it(0)=url,it(1)=uid
})
val pvuv = dataInput
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(1)))
.applyWith(("", List.empty[Int], Set.empty[Int], 0L, 0L))(
foldFunction = {
case ((_, list, set, _, 0), item) => {
val url:String = item(0)
val uid:String = item(1)
(url + "_" + uid, url.hashCode +: list, set + uid.hashCode, 0L, 0L)
}
}
, windowFunction = {
case (key, window, result) => {
result.map {
case (it, list, set, _, _) => {
(it, list.size, set.size, window.getStart, window.getEnd)
}
}
}
}
).keyBy(0)
.flatMapWithState[(String, Int, Int, Long, Long),(Int, Int)]{
case ((key, numpv, numuv, begin, end), curr) =>
curr match {
case Some(numCurr) if numCurr == (numuv, numpv) =>
(Seq.empty, Some((numuv, numpv)))
case _ =>
(Seq((key, numpv, numuv, begin, end)), Some((numuv, numpv)))
}
}
val resulted = pvuv.map(x => {
val keys = x._1.split("_")
(keys(0), x._2, x._3)
})
resulted.print
env.execute("Flink Streaming pv & uv")
}
}
同样的,在nc窗口输入:
url,uid1212
url2,uid1212
url3,uid1212
url,uid1212
url,uid1213
将会在StreamingJob的main控制台看到输出
3> (url,1,1)
5> (url2,1,1)
7> (url3,1,1)
7> (url,1,1)
最后在http://127.0.0.1:8081进行集群(尽管是单节点)进行Job提交,步骤如下
首先生成jar包
mvn clean package
然后将jar文件提交通过web console提交,并启动任务。
最后在nc窗口输入数据,观察stdout的输出结果。
3 问题及下一步
3.1 scala与Flink的版本冲突问题
测试过程中发现scala 2.12.8与Flink 1.8.1-scala_2.12冲突,将StreamingJob切换到scala_2.12.7解决。
问题现象为StreamingJob启动报错
java.lang.NoClassDefFoundError: scala/math/Ordering$$anon$9
Flink项目bug参考:Flink-12461
3.2 Flink核心概念介绍
本文介绍了Flink的两个核心概念:Time与Window,另外还有Trigger、Wartermark、Connector、checkpoint、savepoint等等一系列概念将在后续文章进行介绍。
3.3 单机模式下测试问题
Web Console提交的job无法删除(window平台存在问题,Mac、Linux无问题)